主页 > 下载imtoken钱包20app > 如何做一个区块链浏览器
如何做一个区块链浏览器
对于区块链来说,所有的数据都是公开的,但并不是每个人都可以写代码来查看链上的交易,大多数人会通过一个公共窗口查看数据。这个公共窗口就是区块链浏览器。
区块链上的数据会不断增加,数据的持久化和查询是浏览器的关键。本文将讲解一款区块链浏览器的设计思路。
1.系统设计
当一笔交易上链时,它会存储在链上的账本中,但账本中的数据不能直接显示。因此,需要对这些账本数据进行解析和存储,然后从不同维度展示数据。系统本身并不是很复杂。整体设计如下:
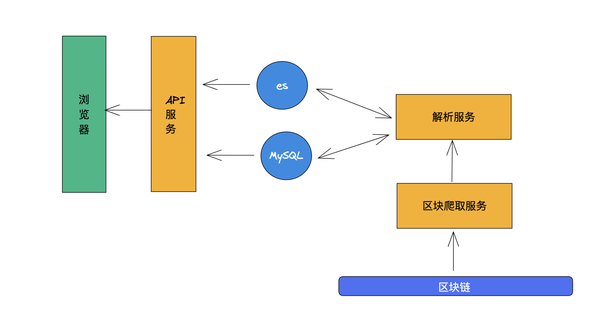
整个系统所做的就是把区块链上的数据拉出来放到数据库中,然后通过一个API服务来实现
系统中有两个重要的部分,一个是块的解析器,一个是拉块的部分。
1.1 存储选择
数据存储的选择非常重要。使用MySQL存储会带来一些问题,字段扩展困难,存储扩展不方便。除了存储,这些数据还需要能够支持多维搜索,这显然是 MySQL 无法满足的。
区块链通常使用kv数据库进行存储区块链浏览器网页,通常是LevelDB、CauchDB、TiKV等,但是这类数据库对搜索的支持很差。对于浏览器来说,搜索是最重要的部分。
这种情况下,ElasticSearch是个不错的选择,ES本身支持大量数据的存储,并且可以支持横向扩展。实时搜索也能满足前端数据展示的需要。
1.2 解析器设计
区块链是一种链状结构,所有区块通过计算前一个区块的哈希值连接在一起:
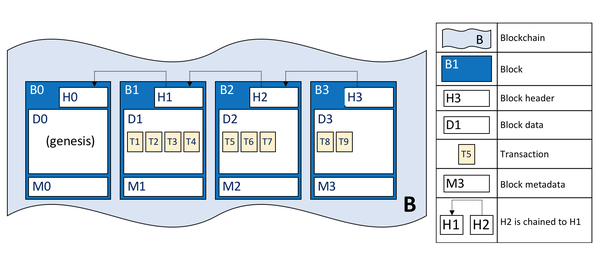
在每个区块中都会打包一系列交易:

在解析区块时,需要不断地逐层打开区块,直到解析完其中的每一笔交易。然后根据不同的分类将它们存储在ES中。这似乎是一个相当复杂的过程,只需设计一个界面即可完成。
1.3 安全注意事项
由于浏览器是一个开放的系统,每个人都可以访问,所以要特别注意系统的安全性,避免有人在攻击系统。这里有两种类型的保护:
在网关层可以部署一些防火墙,在API层可以使用IP限制策略,比如限制同一IP在一段时间内的最大访问频率。尽可能保持浏览器稳定运行。
2.遇到的问题
完成以上设计和实现后,就可以实际使用了。但是在实际使用过程中发现还是存在一些问题。
2.1 如何处理已有数据
从区块链拉取数据时,区块中可能已经有很多数据。如果使用单线程拉取数据可能需要很长时间。由于单线程拉块速度不够快,所以换成多线程,所以换成如下模式:

这种方式,拉取速度快很多,但是如果链上数据很多,这种方式还是不够用,
但是在这里,没有办法通过添加线程来加速拉取。速度。因为在解析块时,会使用一个新线程来解析它。如果块被拉得太快,解析线程的数量会急剧增加,最后程序会崩溃。
所以还有其他方法可以提高拉取速度。
由于单个实例无法持续提升性能,可以通过多个实例来提升,但这会引入一个新的问题,即如何在多个实例之间同步状态。
分析一下区块链浏览器网页,你会发现很多中间数据在区块爬取的过程中是不需要统计的,比如每分钟产生的区块数量,每分钟产生的交易数量。其实只需要在多个实例之间同步block的高度,这样不同的block就可以拉到不同的高度。
这里,为了减少系统的额外依赖,我们最终决定使用MySQL的悲观锁来同步块高,以减少加锁的频率,减少获取锁的时间。同步高度时,会一次性获取一批高度。比如得到10个高度,MySQL中的高度会直接更新10个。
由于每个实例有多个线程拉取数据,避免了拉取时每个线程都获取到一个高度。块高度由实例中的线程数获得。比如线程数是10,那么直接在MySQL中抓取10个高度,然后同时拉取。

这样做后,拉块的速度大大提高。 5000万股数据拉到网上只需要5天左右,完全可以接受。
股票数据拉取后,可以恢复为单实例、多线程拉取模式,可以节省资源。
2.2 块处理失败
在拉块过程中,拉块失败可能有多种原因。此时需要对处理失败的块进行重新处理。
这里的设计中,处理的方式比较简单,将失败的块放入失败,然后会有线程监控失败队列,从中获取高度重新处理。
3.读写分离
但到目前为止,这款浏览器还远非完美。现在block的解析和block的拉取是绑定在一起的,es写的错误也会导致整个block拉取失败。拉取必须通过重试来完成。这会影响整体拉动速度。
随着区块链业务越来越多,出块的速度也越来越快。目前的拉块方式可能跟不上块拉块的速度。因此,需要引入消息队列,将块和块解析功能完全解耦,如下图。
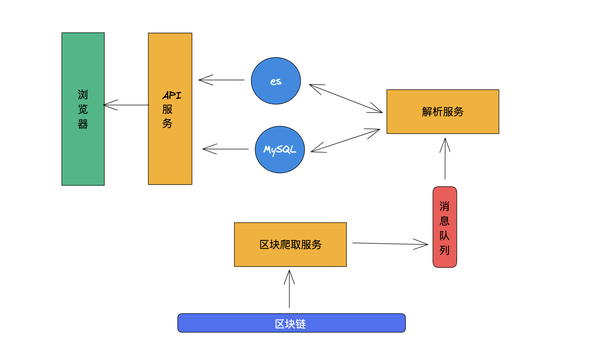
这样拉块和解析不会互相阻塞,系统会更稳定。
文/雷军





